February 23, 2023
What are page ingredients and how to use them

Daniel Dzhenev
A page ingredient is a data ingredient used for building site level knowledge. Unlike keyword ingredients, which are used to understand how users search, page ingredients allow collecting information about a site structure by crawling pages, ingesting taxonomy data, or simply integrating page data from an external source. Later you can combine page ingredients with keyword ingredients to work out for which competitive topics you’re missing pages.
If you wanted to match topics to existing pages or take any other site-level action, such as deduping the site or using internal linking, page ingredients should be used first to get crawled pages data.
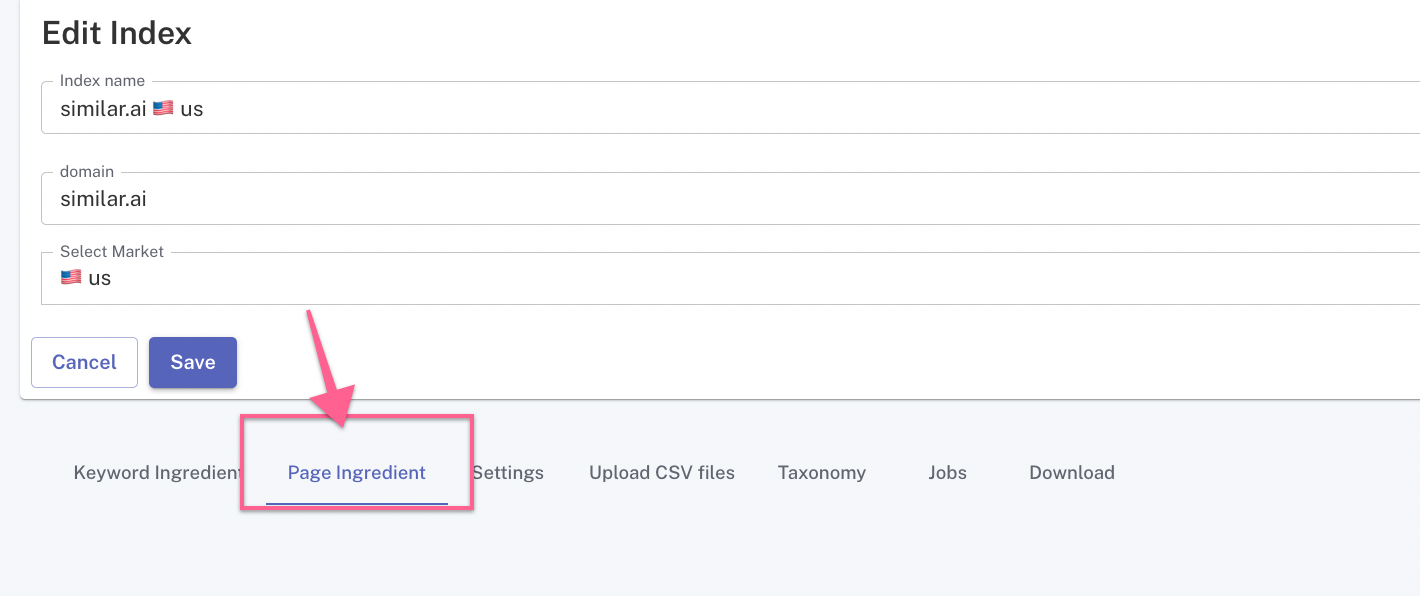
Setup
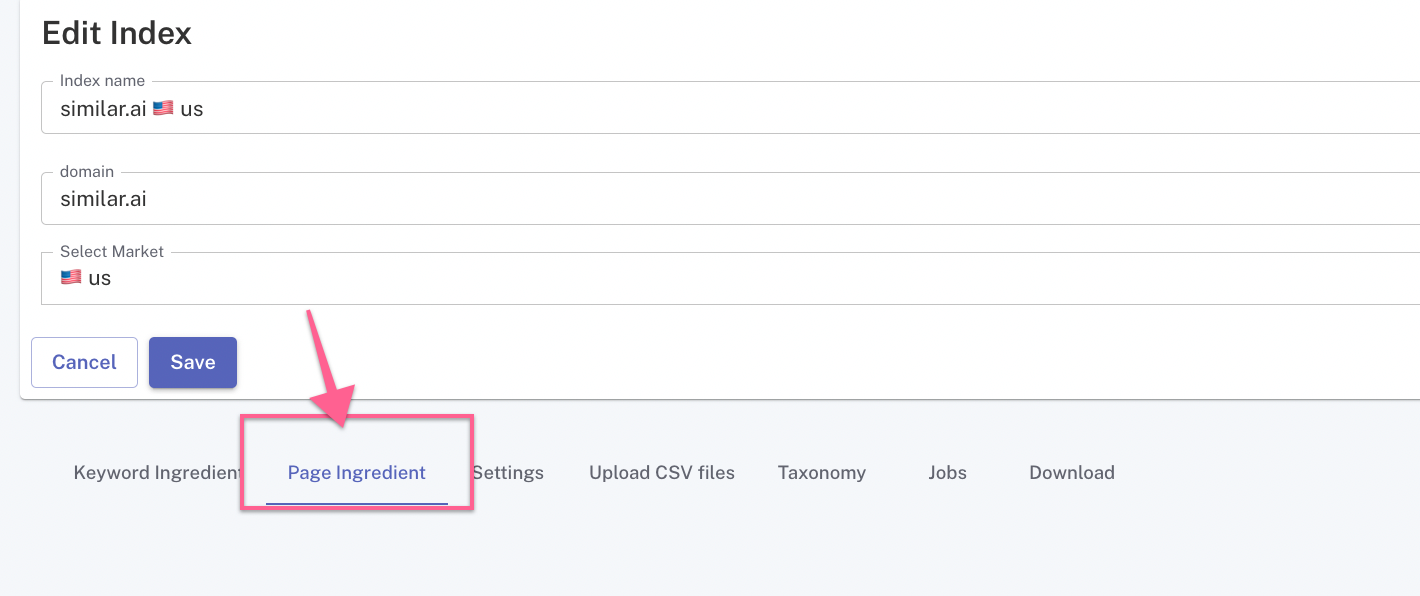
By default, when an index is created and the main domain is added, we will automatically attempt to find the fastest route to crawl pages, normally by discovering the existing XML sitemap in the robots.txt file.
If an up-to-date XML sitemap exists, it will be crawled once the Enabled field button is ticked. Sitemaps discovered in the robots.txt file will be automatically displayed as different options to choose from.

Data sources
Generally, there are a few different options that you can use in Page ingredients to collect page data. You can easily add these using the Add New button.
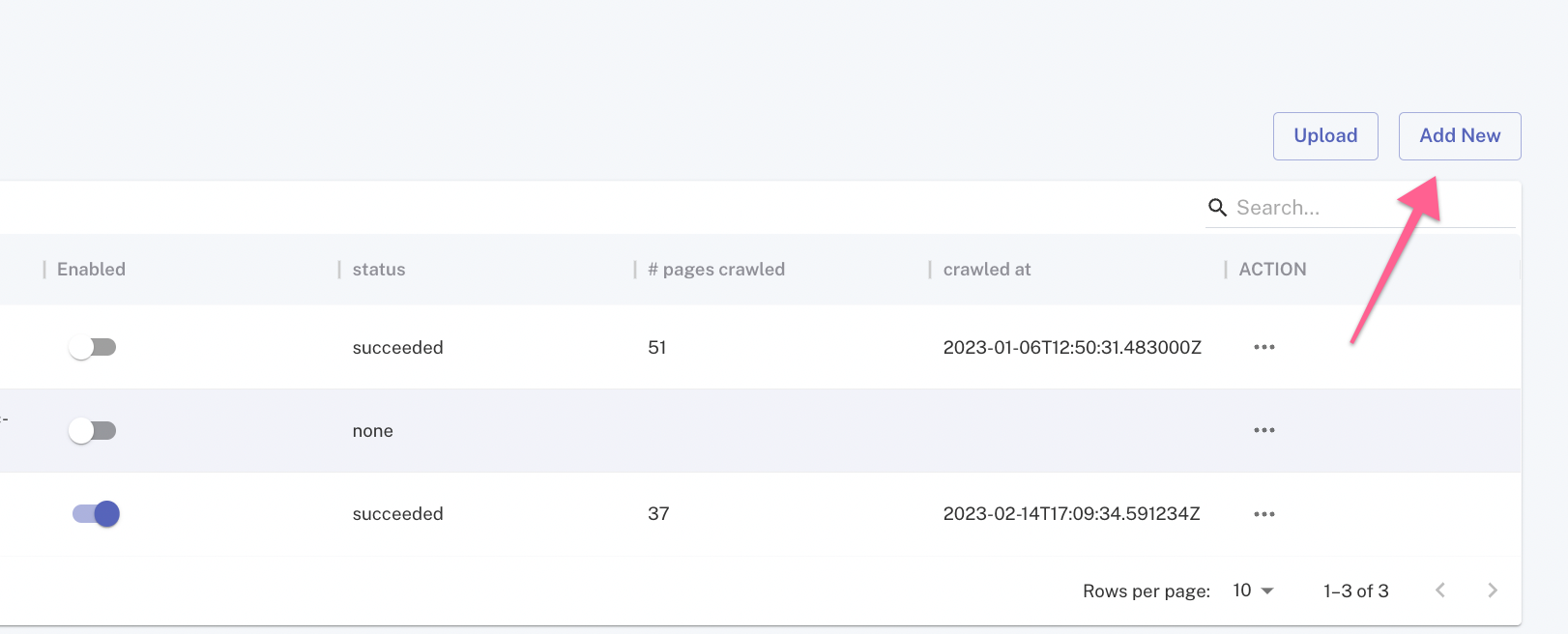
XML sitemaps
XML sitemaps found in robots.txt will be used by default, however, you can also submit sitemaps separately. Please ensure the slider button is enabled.

Crawling
Apart from getting pages from the XML sitemap, you can also request a direct crawl for a website, by selecting the Source as Regular. This will enable a spider crawl from the starting page provided in the URL field.
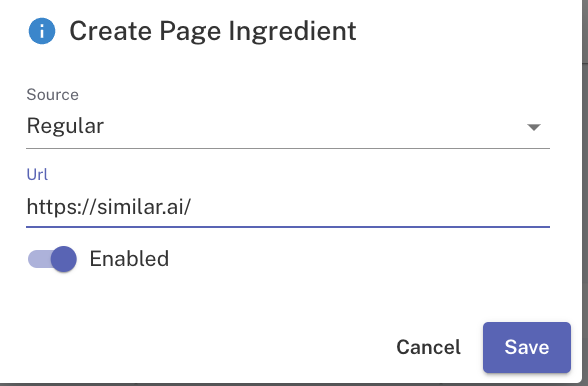
Other internal/external data
You can also add any custom uploads in a .csv format which will be appended to the crawled data. For example, this could be conversion data, GA session data, or simply another crawl export taken from elsewhere, such as Screaming Frog.
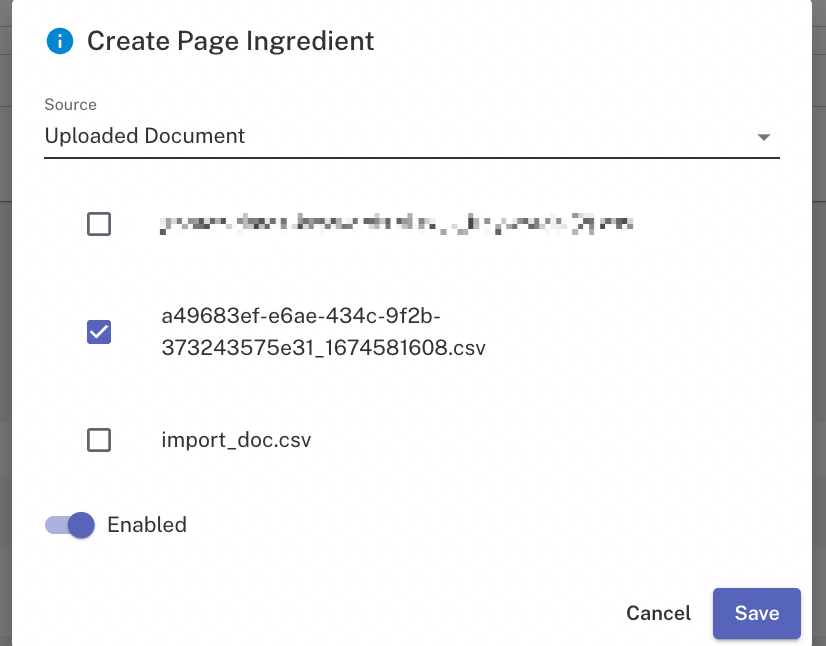
For this, you need to first upload the file by using the Upload button next to Add New. Once uploaded, you can enable the uploaded document to be used as a data source by adding a new page ingredient.
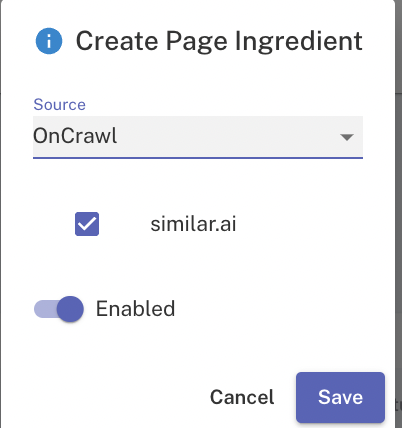
3rd party integrations
If you’re already using cloud crawlers in the likes of OnCrawl or Botify, you can also integrate existing page data by connecting the relevant source.