April 3, 2022
Unlocking Google Search Console API’s Full Potential: Overcoming Limits

Robin Allenson
(Updated 1 September 2024).
Why use the Google Search Console API?
Using the Google Search Console (GSC) data for a site through the Search Console Application Programming Interface (API) instead of the web user interface (UI) has become popular. Making the site’s ranking keywords available in BigQuery to Python code lets you build a range of SEO applications on top, impossible without access to the raw data.
The GSC UI shows benchmark statistics for a site that are neither sampled nor aggregated. However, pulling back keyword data is restricted to 1,000 records, pushing many to use the Search Console API. GSC is a popular SEO ingredient. If you need a Google SEO data API, the GSC API has it all. However, there are misunderstandings around Google Search Console sampling and GSC API limits. How can you get full Google Search Console bulk data into Big Query?
Luckily, we’ve been testing this at Similar.ai for a number of years. We’ve discovered the Search Console limits and how to export Google Search Console data from the API in bulk into Big Query. Read on to learn from our experience.
Does the Search Console limit the data you can retrieve?
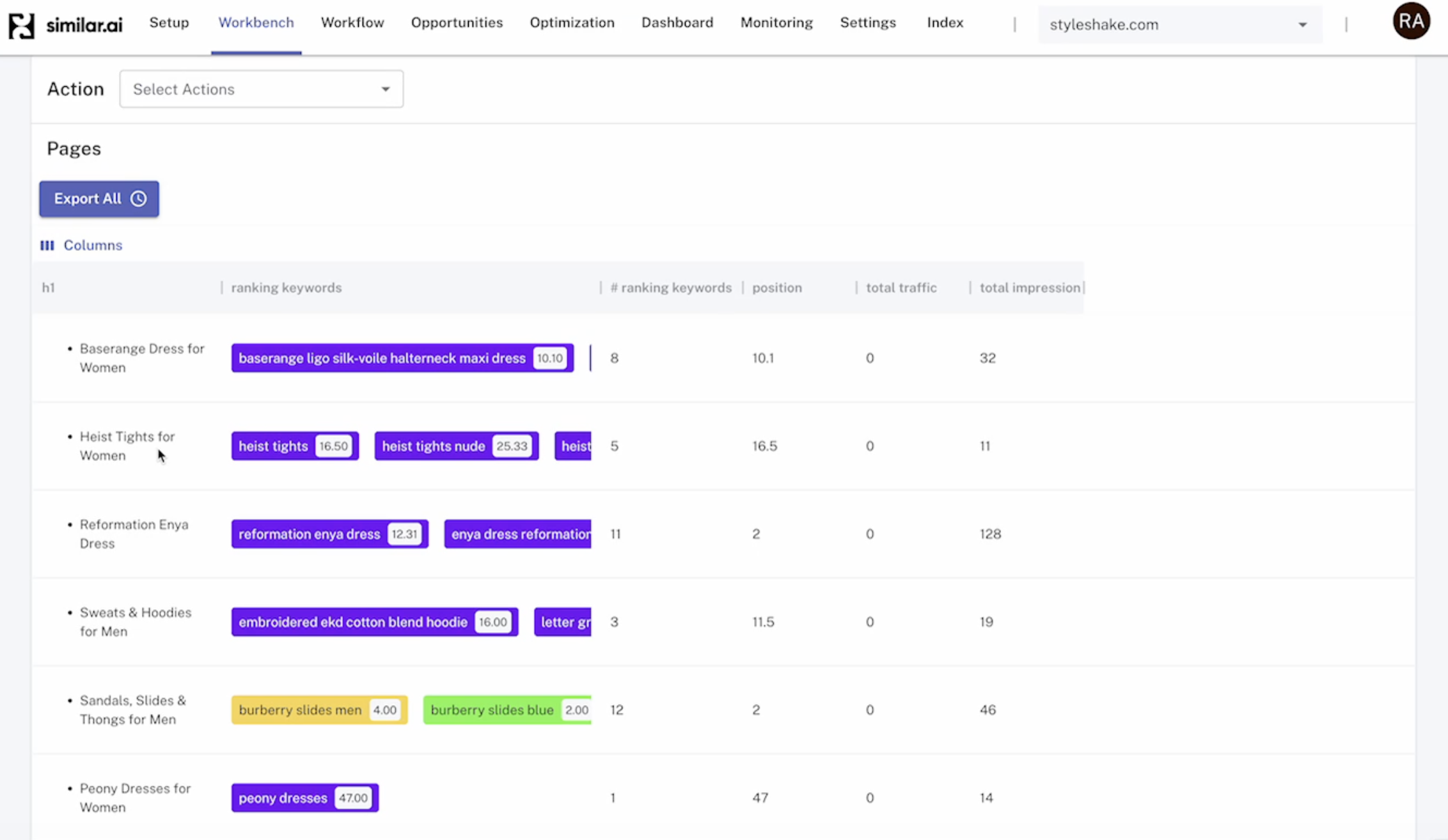
Yes, both Search Console UI and Google Search Console API limit the data you can get. The UI limit is 1,000 records. The same dataset via the GSC API has loss due to aggregation, the long tail data gets clipped and some personally identifiable information (PII) is omitted. For many smaller sites, you can get nearly all the keywords, impressions and clicks through the API. However, the larger sites drop off. These are real Google Search Console API limits that can affect your results. You can only get 50,000 search console page-keyword pairs per GSC property per day.
A product SEO team said that it wasn’t a problem since very few of their pages after the first 1,000 had clicks or impressions. This is a common misunderstanding: the data isn’t the truth, it’s just a piece of the truth. That’s the nature of sampling. That site is ranking for more keywords, with many pages getting one or two impressions and no clicks. However, they assume it’s not true because search console never talks about this. What they see is an artifact of the search console limits. If you’re wondering why your page doesn’t show for any keywords in Google’s best page ranking API, we may have found the reason.
Who are you again?
I’m Robin Allenson, co-founder & CEO at Similar.ai. You might know us from our work on SiteTopic.io for keyword research. My SEO automation company has been researching how to maximize Google keywords from the Google Search Console API. We tested various methods and discovered the Search Console Sampling Gap, which Google doesn’t reveal. Using this, we tested different approaches to retrieve all SEO data via API: missing keywords, clicks, and impressions. We’ve found a simple way to extract bulk data from GSC and export it to Big Query, effectively bypassing GSC API limits.
How can we measure Search Console sampling limits?
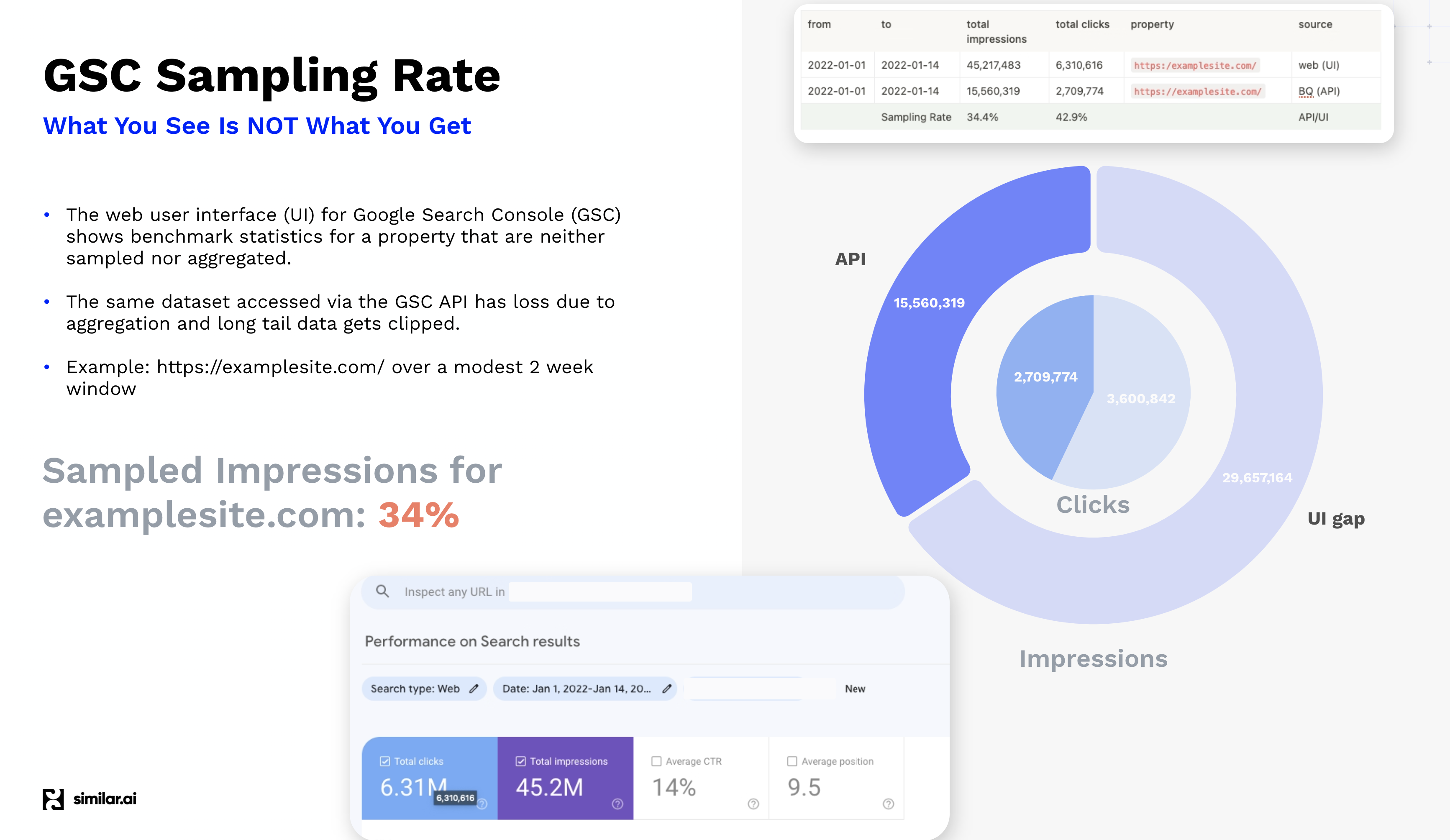
The Search Console Sampling Gap is the difference between the clicks or impressions from keyword-page pairs from the API and the site-level data. We measure the gap by adding the clicks and impressions of the page-keyword pairs from the API and comparing them to the benchmark statistics for the site in the GSC UI. This ratio is the GSC Sampling Rate. The missing clicks or impressions are the GSC Sampling Gap. For large sites, the impressions sampling gap is around 66%. The larger the site, the more significant this issue becomes.
Large sites miss 66% of their GSC API impressions due to Search Console limits.
How much data from the Google Search Console API does a product SEO site miss?
What if this isn’t just a large site, but a huge one? The differences are consistent between the Google Search Console API and a full bulk data export of Google Search Console keywords. Google sampling limits your understanding of your site.
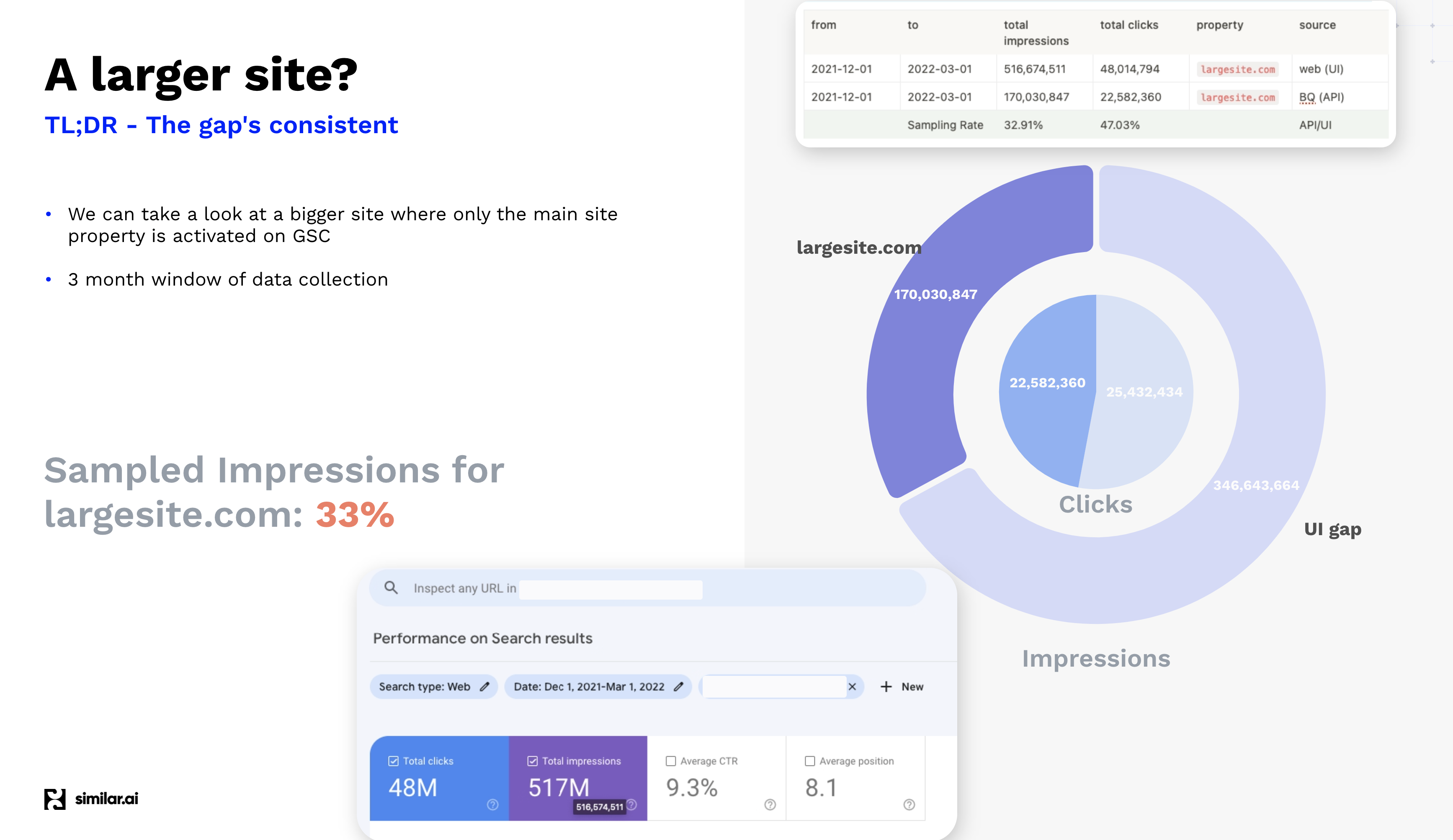
Huge sites miss 67% of their GSC API impressions due to Search Console API limits.
We believe the consistency between two enterprise site sizes is that the site profile data measures the fat tail size. I’ve spoken to product-led growth teams with single-digit % sample rates: they hit these SEO keyword limits over 90% of the time. They need their enterprise SEO platform to scale, but it’s hard without Search Console data: they lacked visibility until they partnered with Similar AI for full search console data in a bulk export.
How big a problem are Google Search Console API limits?
How problematic is missing GSC API data for your downstream applications? If you’re primarily using GSC data for analytics, maybe not much. However, if you want to use GSC data for SEO automation, such as cleaning up low-quality pages, enhancing internal linking to money pages, or creating new pages for unique user needs, data gaps become critical.
Deep site structures mean worse impact from large GSC limits.
Some large sites have a directory structure that makes Search Console data sampling unreliable. Missing data isn’t spread evenly; instead, there’s no data on specific pages or categories. If your downstream product SEO goal is to use GSC data to identify relevant topics where your site ranks poorly and lacks a dedicated category page, this folder structure and the GSC API for enterprise sites will result in missed impression data and no new page recommendations. If a category is in the 5% that drive all your revenue, that’s a significant problem.
The folder structure of enterprise sites doesn’t explicitly mention their higher-level categories in the directory path for lower-level ones. This is common. Probably missing out higher-level categories in the URLs of deeper categories happens often because many sites are huge and many enterprise sites have deep structures. Deep structures are common in classifieds, affiliate, travel, real estate, eCommerce, and marketplace sites. Not mentioning higher-level categories helps keep URLs short when a site has thousands of categories.
The clutch category on Farfetch is https://www.farfetch.com/shopping/women/clutches-1/items.aspx, but the breadcrumbs are Women > Bags > Clutch Bags. If you followed the standard practice of adding properties for the main top-level categories like https://www.farfetch.com/shopping/women/, you’d miss a lot of data for hundreds of directories underneath it. It’s not just a subtle Google Search API limit; you’d see no GSC API data when those pages rank and should see GSC keywords. If your site has this deep structure, adding an internal linking structure around user needs will help simplify it to grow your active pages.
We love sites with deep (or flat) structures, as they pose no issue for our bulk data export for GSC! If that’s your site or your client’s, let us know, and we can activate the Google Search Console firehose.
Why missing GSC API data can undermine your SEO experimentation efforts
The second issue with missing GSC data through the API is tracking the impact of product SEO changes. Growing organic revenue is influenced by many factors. We’ve spoken to SEO teams who use their internal data analytics team to measure the impact of their initiatives. That is logical as these teams can use a consistent measure approach for all marketing initiatives. The top approach is using a causal impact analysis of traffic. This requires months of data, weeks for the analysis, and mostly delivers inconclusive outcomes.
Different product SEO experiments target different SEO elements. For example, optimizing a page by adding meta-data, semantic markup or focusing it around topics, not keywords, will likely improve the CTR. Adding FAQs to a long-tail transactional page will likely improve the number of keywords it ranks for and reduce the average position. Internal linking, such as boosting links to pages with traffic and revenue, can improve the position and grow organic revenue. These can often be measured in days or weeks with solid GSC data. According to the head of analytics & machine learning for a huge enterprise site, this bulk data export is both “more robust and more sensitive.”
It’s much faster. The time to learn from SEO experimentation automation is reduced. For product-led teams, the ability to learn quickly from multiple experiments in your vertical and each geo is a superpower. It all stems from having accurate, granular, and comprehensive GSC data as a bulk export for every page and category on your site. Without that data, you’ll learn slower than your organic competition.
What are the limits of the Search Console?
The Google Search Console UI limits 1,000 rows, but API data retrieval is subject to quotas at site, account, and property levels. You can get 50,000 pairs of pages & keywords per search console property daily. Adding new properties increases API data retrieval. We track the sample gap to monitor the click, impressions, or keywords gap reduction as we add properties. How much can we reduce the gap?
How to obtain all first-party demand data despite Google Search Console sample limits
Knowing which properties to add can significantly reduce the gap. By selecting 50 properties and adding them to our example site, we reduced the impressions lost from the API data retrieval six-fold from a 67% gap to just 11%.
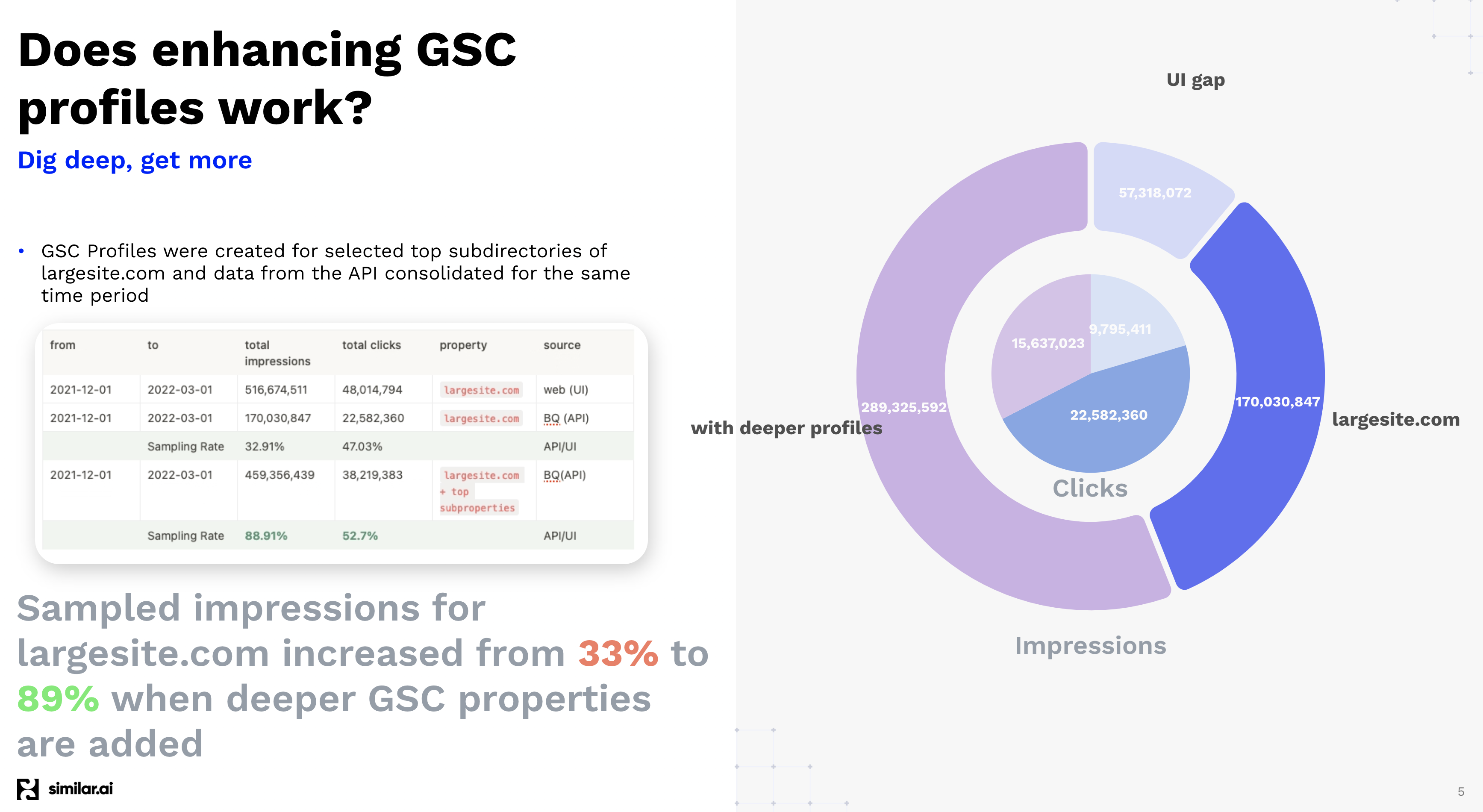
Adding more GSC properties reduces the lost impression data through the API six-fold.
That’s amazing and useful for product-led SEO teams with deep site structures. But how far can we take this approach? There’s a point where the benefits decrease because of the enormous long tail.
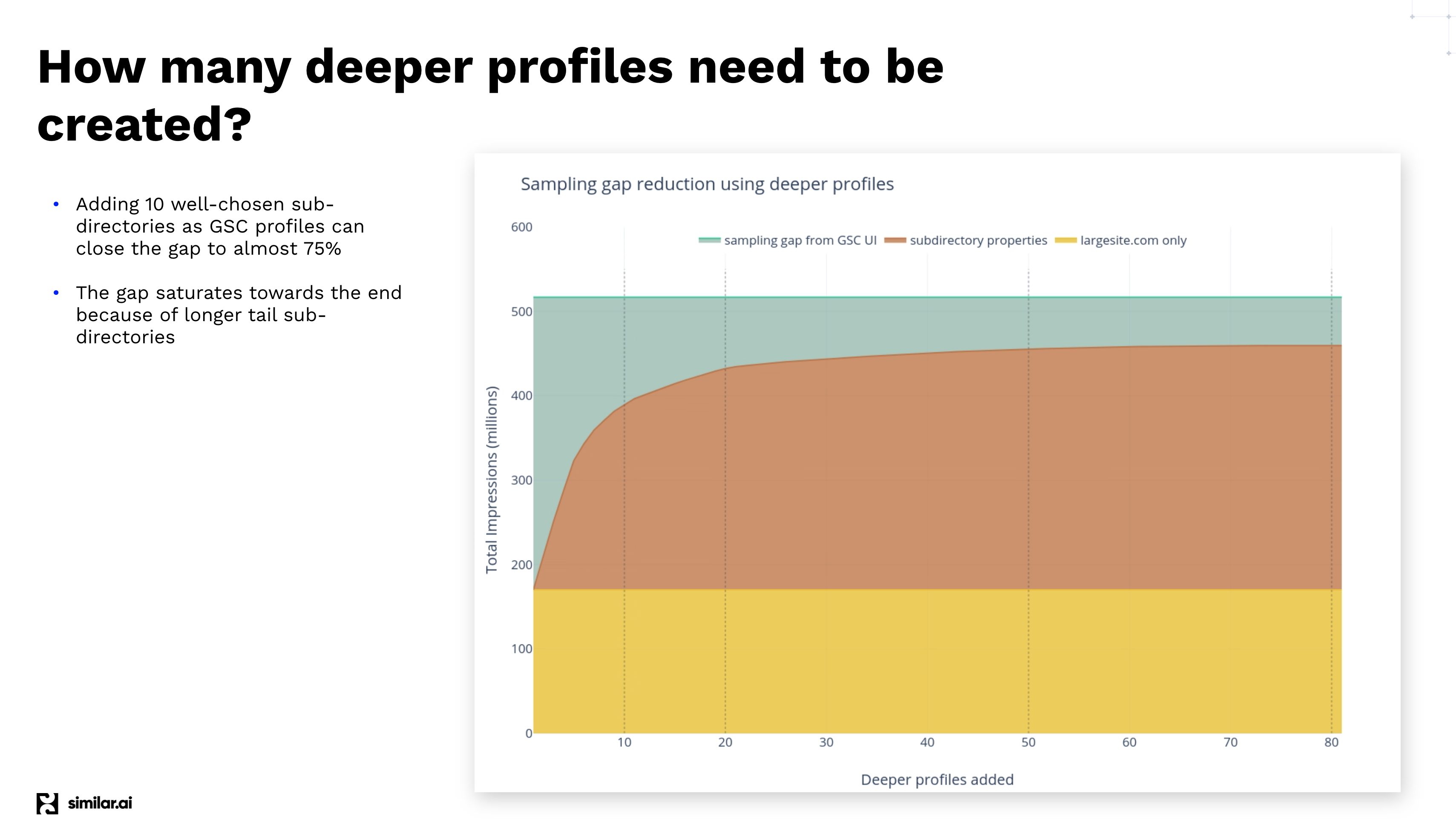
Adding more GSC profiles closes the Search Console’s sampling gap.
The more profiles we add, the fewer impressions and clicks we get. More subdirectories yield less data to shrink the API gap. This slow, meticulous process is important to build up nearly all the first-party search engine data for an enterprise.
Enterprise SEO teams miss 90% of Google Search Console keywords.
The Similar.ai platform can access nearly all data from Google for any site, regardless of size, although some data will always be withheld.
There’s another amazing benefit. I’ve spoken to many product-led growth teams, and almost all are unaware of this. Although the reduction in the impression or click sampling gap diminishes with each additional profile, the number of keywords increases dramatically due to the long tail. For a recent customer, we increased the number of keywords by 13.7x. You can close the keyword gap — closing the SEO gap for many product-led growth companies.
Using 14x the number of keywords to build machine learning classifiers
A great application of this significant improvement in keywords for your site is to build AI for SEO. In AI, more training data means better results. You can use the new keywords to improve machine learning classifiers to disambiguate keywords and enhance enterprise SEO product features.
Using your GSC BigQuery keywords to get topics
One downside to this rich keyword data is that you can’t focus on the important details because of the overwhelming information. This is where a shift from keyword-centric to topic-centric analysis becomes crucial. We leverage SiteTopic.io to transform this vast sea of keywords into structured, meaningful topics.
SiteTopic.io employs advanced Large Language Models (LLMs) and other sophisticated tools to perform Named Entity Recognition (NER) on the keywords. This process adds much-needed structure to the messy demand data that the GSC BigQuery export or API delivers. By doing so, we can extract and organize the underlying themes and concepts that users are actually searching for.
This approach offers several advantages:
1. Simplified Analysis: Instead of sifting through thousands of individual keywords, you can focus on broader topics that encompass multiple related keywords.
2. Better Content Strategy: Understanding topics allows you to create more comprehensive, user-centric content that addresses the full scope of user intent.
3. Improved Relevance: By targeting topics rather than individual keywords, you’re more likely to rank for a wider range of related searches.
4. Efficient Resource Allocation: You can prioritize your SEO efforts on high-value topics rather than getting lost in the minutiae of individual keywords.
5. Future-Proofing: As search engines become more sophisticated in understanding context and user intent, a topic-based approach aligns more closely with these advancements.
By transforming your raw GSC keyword data into structured topics, you gain a clearer, more actionable view of user demand. This allows you to make more informed decisions about content creation, site structure, and overall SEO strategy, ultimately leading to better organic search performance.
Are you scaling your GSC data for product SEO initiatives?
Are you curious about the practical implications of search console limits and the GSC data you miss? We can measure that for your site. If you’d like to skip the queue and get a reliable bulk data export for Google Search Console from experts, please contact us, and we’ll set you up! Just contact us here.
We’d love to swap notes on how leading product growth teams use GSC data for internal linking, clean-up, new page creation, automated content generation, or experimentation & measurement. We enjoy discussing the challenges and successes of product-led SEO.
We’re working with global clients to maximize their SEO data. Our platform integrates first-party and third-party data; works with crawlers, log file analyzers, and keyword tools; automates & updates; connects pages data with SERP, keyword, topic & knowledge graph data; automates conclusions for every page on your site; all to let you experiment and scale your SEO initiatives.